Abstract
In this paper, we introduce LangSplatV2, which achieves high-dimensional feature splatting at 476.2 FPS and 3D open-vocabulary text querying at 384.6 FPS for high-resolution images, providing a 42 × speedup and a 47 × boost over LangSplat respectively, along with improved query accuracy. LangSplat employs Gaussian Splatting to embed 2D CLIP language features into 3D, significantly enhancing speed and learning a precise 3D language field with SAM semantics. Such advancements in 3D language fields are crucial for applications that require language interaction within complex scenes. However, LangSplat does not yet achieve real-time performance (8.2 FPS), even with advanced A100 GPUs, severely limiting its broader application. In this paper, we first conduct a detailed time analysis of LangSplat, identifying the heavyweight decoder as the primary speed bottleneck. Our solution, LangSplatV2 assumes that each Gaussian acts as a sparse code within a global dictionary, leading to the learning of a 3D sparse coefficient field that entirely eliminates the need for a heavyweight decoder. By leveraging this sparsity, we further propose an efficient sparse coefficient splatting method with CUDA optimization, rendering high-dimensional feature maps at high quality while incurring only the time cost of splatting an ultra-low-dimensional feature. Our experimental results demonstrate that LangSplatV2 not only achieves better or competitive query accuracy but is also significantly faster.
Speed of High-dimensional Feature Rendering
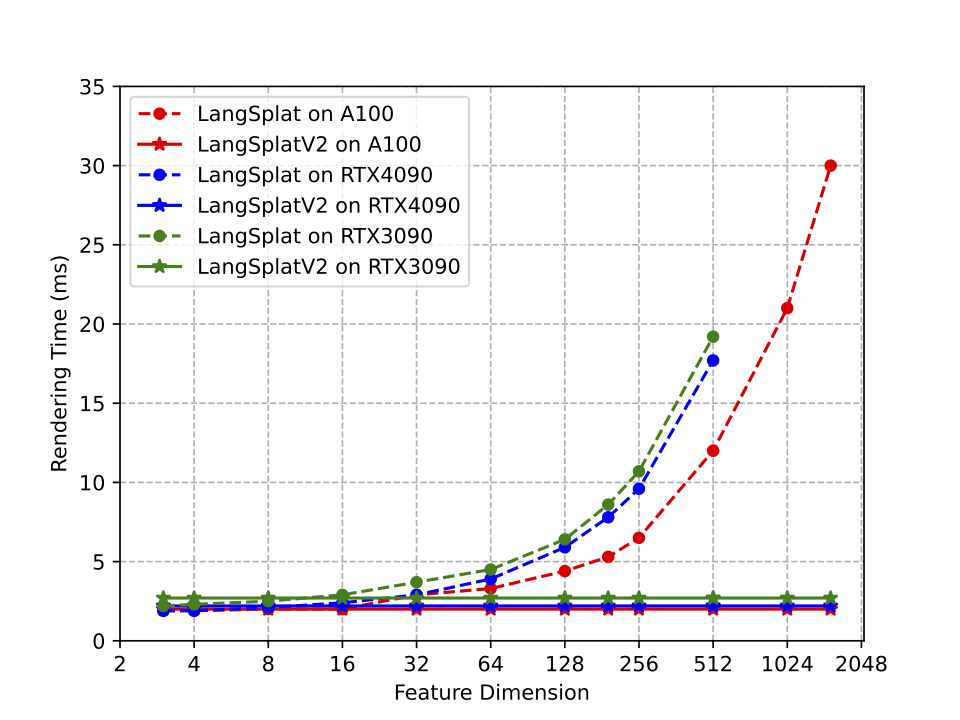
This figure shows feature rendering time comparison with different GPUs. Note that the less advanced GPUs (RTX 3090 and RTX 4090) cannot accommodate the LangSplat model with feature dimensions of 1024 or higher due to running out of memory. As we can see, our LangSplatV2 successfully decouples rendering speed from the dimensionality of rendering features, enabling the rendering of high-dimensional features at the computational cost of splatting an ultra-low-dimensional feature.

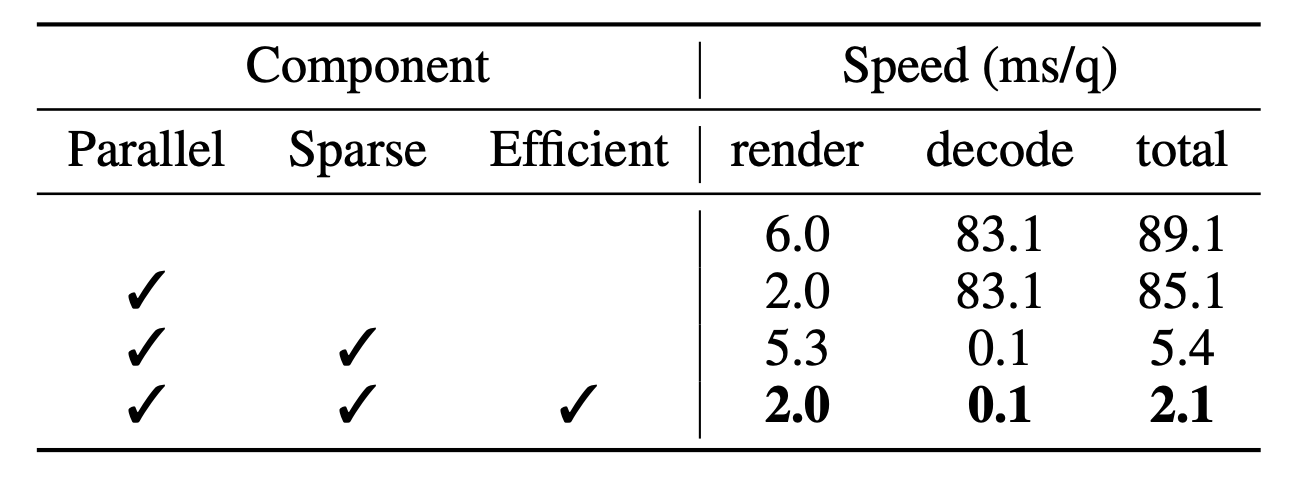
These figures show our contributions to inference speeding up. Rendering three semantic levels in parallel can reduce the rendering time from 6.0 ms to 2.0 ms per query. The sparse coefficient field can significantly speed up the decoding stage from 83.1 ms/q to 0.1 ms/q by changing the heavy weight decoder to a simple matrix multiplication operation. Efficient sparse coefficient splatting method effectively transformed the 192-dimensional rendering into 12-dimensional rendering, reducing the rendering time from 5.3 ms to 2.0 ms per query through CUDA optimization.
Visualization of Open-vocabulary 3D Query
Visualization of the open-vocabulary 3D object localization results. We observe that our LangSpaltV2 can give more accurate localization predictions compared with LangSplat. For example, our LangSplatV2 can give the correct prediction for "pumpkin" while LangSplat entirely fails in this query.
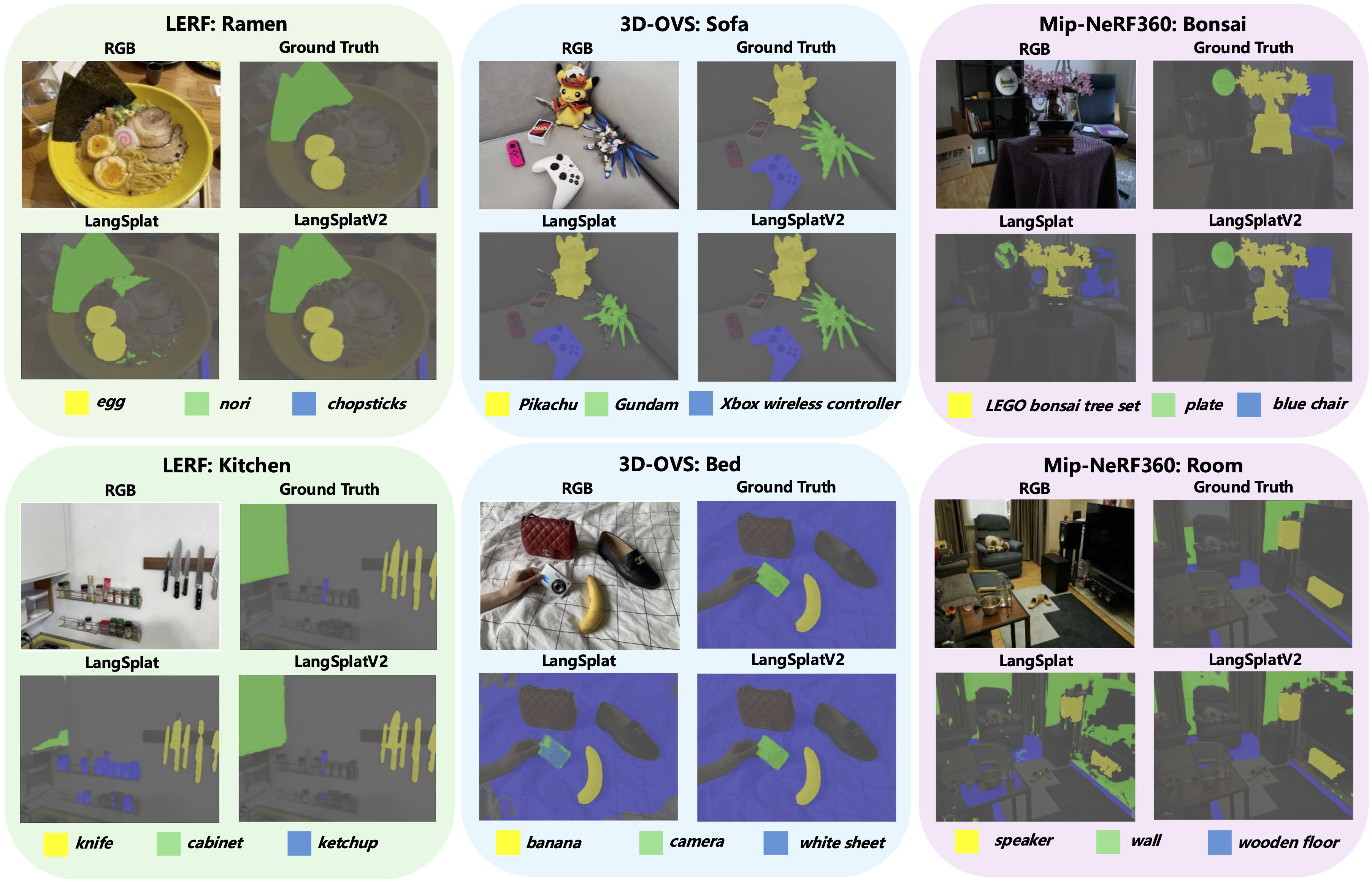
Visualization of the open-vocabulary 3D segmentation results in three datasets. We observe that our LangSplatV2 can generate more accurate masks compared with LangSplat. For example, in the "Kitchen" scene, LangSplat predicts a noisy mask for the "ketchup" query, while our LangSplatV2 generates more precise and clean masks.
BibTeX
@article{li2025langsplatv2highdimensional3dlanguage,
title={LangSplatV2: High-dimensional 3D Language Gaussian Splatting with 450+ FPS},
author={Wanhua Li and Yujie Zhao and Minghan Qin and Yang Liu and Yuanhao Cai and Chuang Gan and Hanspeter Pfister},
year={2025},
eprint={2507.07136},
journal={Advances in Neural Information Processing Systems},
archivePrefix={arXiv},
primaryClass={cs.GR},
url={https://arxiv.org/abs/2507.07136},
}